自キ初心者が自作ケース沼まで着々と浸かる話
この記事はキーボード #2 Advent Calendar 2020の23日目の記事です。
はじめまして、こんにちは。bbrfkr(ビビリフクロウ)と申します!
本記事では9月に自作キーボードを初めて、キット組み立て沼から基板設計沼を経由し、自作ケース沼にハマりかけている初心者のお話を書きたいと思います。
8月の終わりに、ITエンジニアコミュニティの皆さんと秋葉原に行く機会がありました。お昼ご飯から早めに集まった私を含むメンバーは、ご飯の後、目的の時間までの余裕があったので、遊舎工房に立ち寄ることになります。そこで私は初めて分割キーボードを目の前にしました。
当初は、「そんなキーボードもあるのねー」くらいの感想だったことを覚えています。しかし、次の日になっても遊舎工房のあの光景が脳裏から離れませんでした。私はたまらず週末に再び遊舎工房を一人で訪れ、店員さんのアドバイスの下、Corne Cherry v2キーボードを手にしました。私は自キの沼に足を踏み入れてしまったのです。9月の1週目のことです。

そこからはキーボードのことが常に頭の中にありました。Corne Cherryを手に入れた私はまず、40%キーボードに慣れるため、タイピングの練習をはじめました。Typing Clubに大変お世話になりました。親指でスペースやエンターを押すことにも慣れ、私はこの時点でこれまでのノートPCについているキーボードと決別することになりました。
Corne Cherryでタイプすることになれると、今度は小指に6つものキーを担当させることに違和感を覚えるようになりました。自作キーボードでも、キースイッチやキーキャップを交換することで打鍵感は変えられても、そもそものキー配列を変えるためにはキーボード自体を変えるほかありません。そこで、もっとすべての指にそれ相応の役割を担当させるキー配列を探し求めることになりました。結果、uzu42キーボードにたどり着きます。これがおよそ9月末のことです。

uzu42を手にした私は4行目のキーに外側から小指、薬指、中指をそれぞれ1キーずつ、残りの3つは親指に担当させることに決めました。この役割分担は少しの間は快適でした。小指を無理に動かさずに薬指と中指に役割を分散させることができました。ですがしばらくすると、親指は結局の所一番内側のキーしか叩いていないことに気づいてしまったのです。私の親指は手の内側に曲げることを極端に嫌っていたのです。
親指がうまく活用できていないことに気づいた私はまた別のキーボードを探し始めました。しかし私のニーズである、各指になるべく役割を分散し、親指をなるべく手の内側に曲げなくて済むような配列を持つキーボードは見つかりませんでした。そこで、私はキーボードを基板から作ることを決心しました。10月の1週目、基板から作る手法を知らない私はまず、SU120を購入し、プロトタイプをまず作ってみようと思い立ちました。ハンダ付けのやり方を習得していた私は、プロトタイプの作成を難なく行うことができました。

プロトタイプができると、次に基板を設計するべく、自作キーボード設計入門を読み込みました。すぐにkicadとinkscapeをインストールし、休日丸一日を使って、オリジナルキー配列を持つ基板を作り上げることができました。プロトタイプの作成、自作キーボード設計入門の読み込みを経ると10月下旬くらいになっていました。ガーバーファイルを得ることができたので、基板制作発注を行います。基板がくるのが待ち遠しい現象は、小さい頃、発売前の新作ゲームを待ちわびるワクワク感に似ていました。
到着した基板を使ってキーボードを組み立てると、私はそのキーボードにScatter42という名前をつけました。このキーボードが生まれたのは自キ界隈の先駆者のおかげだと考えたため、オープンソースとして公開、また遊舎工房にて委託販売することを考えました。それが11月上旬頃です。実際の公開、販売にこぎつけられたのは11月下旬頃になっていました。

Scatter42を作り上げた私はまた少しの間、そのキー配列を純粋に楽しむことができていました。ところが、これまで40%キーボードに慣れていた手はもはやデフォルトレイヤに多くの修飾キーを必要としていませんでした。そこで修飾キーを極力削った新しいキーボードを開発することにしました。lowerとraiseキー以外にデフォルトレイヤには左右のCtrlおよびShiftキーしか無いキーボードが出来上がりました。私はこのキーボードに、今の私にとって、打鍵効率を考えた最少キー数であることから、quantum(量子)と名付けました。現時点ではこのキーボードは販売していませんが、もしご興味がある方がいらっしゃいましたら考えます。。。 quantumが完成したのがちょうど12月上旬でした。

そしていま私はこのquantumを常用していくためのケース設計にいそしんでいる最中です。現状は写真のようなかんたんなケースをOpenScadを使って作成しています。

4ヶ月、短いようで私にとっては濃く長い期間を過ごしました。すべての人を満足させられるキーボード配列はないと思います。今あるキーボード達の配列に満足しきれていない方がいらっしゃいましたら、是非、自作基板設計に踏み込んで頂くきっかけに本文章がなれば幸いでございます。
この文章はquantumを使って書きました。ここまで読んでいただき、ありがとうございました!
SlackとGitlabを連携して社内IT部門への依頼をやりやすくした話
背景
弊社では、GitLabをメインリポジトリとして活用しておりまして、社内ITの依頼管理に対してもGitLab上のissue機能を使って管理しております。ところがこの管理には以下のような課題が在りました。
- 実際の依頼はGitLab上に直接記入するのではなく、Slackで飛んでくることのほうが多い
- issueの起票形式が起票者によってばらつきがある
- issueの起票フォーマットがMarkdownであるため、非エンジニアの方がGitLab上に直接起票するのが難しい
そこで、Slack APIを使ってSlackからの依頼を自動的にGitLabのissueとして起票する仕組みを考えることにしました!
仕組み
仕組みはシンプルで、AWSのAPI GatewayとLambdaを使ってAPIを作成し、Slackの特定のSlashコマンドが叩かれたら以下のようなフローを持って、issueをGitLabに自動作成するようにしています。
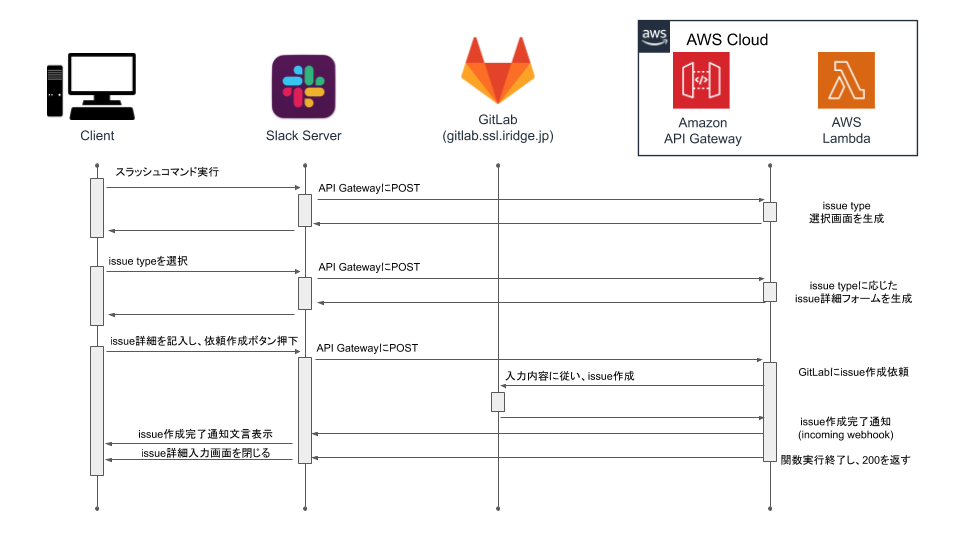
より詳細はslideshareに公開しているため、こちらをご覧いただければ幸いです。
www.slideshare.net
まとめ
実運用を初めて2、3ヶ月くらい経ちますが、特に大きな問題もなく、本ツールを導入することでSlackに窓口を一本化、依頼者が手軽にフォーム形式で起票可能となり、メリットがでてきているようです。是非是非、本記事をご覧いただいた方もSlackを用いた業務オートメーションにチャレンジしてみてはいかがでしょうか!
cdktfをOpenStackでつかってみた
はじめに
プロジェクトでAWS CDKを使う機会が増えています。linterやテストコード書いてCI回したり、静的型付けを実施できたりと、今までインフラの世界では通用しなかった高級言語のナレッジが適用できるようになって嬉しいですよね! そこで、自宅で立てているOpenStackでも同様の恩恵が得られないかと調べていたところ、cdktfで取り急ぎ高級言語化できそうだったので、今回試してみました。。。
実際に使ってみた
cdktfはterraformをcdkフレームワークにくるんだプロダクトです。terraformにはOpenStackのプロバイダも用意されているので、このプロバイダを使ってOpenStackもcdkの世界につれてくることができます!
まずはcdktfプロジェクトを作成しましょう。
$ mkdir cdk-openstack
$ cd cdk-openstack
$ npm install -g cdktf-cli
$ npx cdktf init --template="typescript" --local
Note: By supplying '--local' option you have chosen local storage mode for storing the state of your stack.
This means that your Terraform state file will be stored locally on disk in a file 'terraform.tfstate' in the root of your project.
We will now set up the project. Please enter the details for your project.
If you want to exit, press ^C.
Project Name: (default: 'cdk-openstack')
Project Description: (default: 'A simple getting started project for cdktf.')
npm notice created a lockfile as package-lock.json. You should commit this file.
+ cdktf@0.0.18
+ constructs@3.2.51
added 4 packages from 4 contributors and audited 4 packages in 0.482s
found 0 vulnerabilities
npm WARN eslint-plugin-react@7.21.5 requires a peer of eslint@^3 || ^4 || ^5 || ^6 || ^7 but none is installed. You must install peer dependencies yourself.
+ cdktf-cli@0.0.18
+ @types/node@14.14.10
+ typescript@4.1.2
added 226 packages from 142 contributors and audited 231 packages in 8.713s
54 packages are looking for funding
run `npm fund` for details
found 0 vulnerabilities
> cdk-openstack@1.0.0 build /home/ubuntu/workspaces/gitlab-com/cdk-openstack
> cdktf get && tsc
Generated typescript constructs in the output directory: .gen
========================================================================================================
Your cdktf typescript project is ready!
cat help Print this message
Compile:
npm run compile Compile typescript code to javascript (or "npm run watch")
npm run watch Watch for changes and compile typescript in the background
npm run build cdktf get and compile typescript
Synthesize:
cdktf synth Synthesize Terraform resources from stacks to cdktf.out/ (ready for 'terraform apply')
Diff:
cdktf diff Perform a diff (terraform plan) for the given stack
Deploy:
cdktf deploy Deploy the given stack
Destroy:
cdktf destroy Destroy the stack
Upgrades:
npm run get Import/update Terraform providers and modules (you should check-in this directory)
npm run upgrade Upgrade cdktf modules to latest version
npm run upgrade:next Upgrade cdktf modules to latest "@next" version (last commit)
Use Prebuilt Providers:
You can add one or multiple of the prebuilt providers listed below:
npm install -a @cdktf/provider-aws
npm install -a @cdktf/provider-google
npm install -a @cdktf/provider-azurerm
npm install -a @cdktf/provider-docker
npm install -a @cdktf/provider-github
npm install -a @cdktf/provider-null
Check for an up to date list here https://github.com/terraform-cdk-providers
========================================================================================================
$
できたプロジェクト内部はこんな感じです。
$ ls cdktf.json help main.d.ts main.js main.ts node_modules package-lock.json package.json tsconfig.json $
cdktf.json をのぞいてみると、awsプロバイダしか定義されていないのがわかります。
{
"language": "typescript",
"app": "npm run --silent compile && node main.js",
"terraformProviders": [
"aws@~> 2.0"
],
"context": {
"excludeStackIdFromLogicalIds": "true",
"allowSepCharsInLogicalIds": "true"
}
}
なので、 terraformProviders から aws を削除し、terraform-provider-openstack/openstack@1.33.0 を追加し、cdktf get を叩きます。
{
"language": "typescript",
"app": "npm run --silent compile && node main.js",
"terraformProviders": [
"terraform-provider-openstack/openstack@1.33.0"
],
"context": {
"excludeStackIdFromLogicalIds": "true",
"allowSepCharsInLogicalIds": "true"
}
}
$ npx cdktf get Generated typescript constructs in the output directory: .gen $
さて、そうしたら実際にインフラコードを書いていきましょう! main.ts をのぞいてみると、、、
import { Construct } from 'constructs';
import { App, TerraformStack } from 'cdktf';
class MyStack extends TerraformStack {
constructor(scope: Construct, name: string) {
super(scope, name);
// define resources here
}
}
const app = new App();
new MyStack(app, 'cdk-openstack');
app.synth();
とにもかくにもopenstackモジュールをimportしましょう。以下のimport文を追加します。
import * as openstack from './.gen/providers/openstack';
そうしたら、 // define resources here 以降に認証情報やOpenStackリソースを定義していきます。まずは認証情報から、以下のように与えます。
new OpenstackProvider(this, "openstack-provider", {
userName: process.env.OS_USERNAME,
password: process.env.OS_PASSWORD,
tenantName: process.env.OS_PROJECT_NAME,
userDomainName: process.env.OS_USER_DOMAIN_NAME,
projectDomainName: process.env.OS_PROJECT_DOMAIN_NAME,
authUrl: process.env.OS_AUTH_URL,
cacertFile: process.env.OS_CACERT
});
openrc認証情報を使えるように、環境変数でパラメータを与えておきます。
次に、リソース定義をこんな感じで定義していきますー。
// define network for octavia
const octaviaNetwork = new openstack.NetworkingNetworkV2(this, "OctaviaVlanProviderNetwork", {
name: "lb-mgmt-net",
external: true,
shared: true,
mtu: 1450,
segments: [
{
physicalNetwork: "octavia_vlan_provider",
segmentationId: 121,
networkType: "vlan"
}
]
});
// define subnet for octavia
const octaviaSubnetCidr = "192.168.121.0/24";
new openstack.NetworkingSubnetV2(this, "OctaviaVlanProviderNetworkSubnet", {
name: "lb-mgmt-subnet",
cidr: octaviaSubnetCidr,
networkId: octaviaNetwork.id,
allocationPool: [
{
start: "192.168.121.100",
end: "192.168.121.254"
}
],
gatewayIp: "192.168.121.1"
});
// define security group for amphora
const amphoraSecurityGroup = new openstack.NetworkingSecgroupV2(this, "AmphoraSecurityGroup", {
name: "amphora-sg",
});
const amphoraSgIngressMaps = [
{
protocol: "tcp",
portRangeMax: 22,
portRangeMin: 22,
remoteIpPrefix: "0.0.0.0/0"
},
{
protocol: "tcp",
portRangeMax: 9443,
portRangeMin: 9443,
remoteIpPrefix: octaviaSubnetCidr
},
{
protocol: "tcp",
portRangeMax: 5555,
portRangeMin: 5555,
remoteIpPrefix: octaviaSubnetCidr
}
];
for (const [index, amphoraSgIngressMap] of amphoraSgIngressMaps.entries()) {
new openstack.NetworkingSecgroupRuleV2(this, `AmphoraSgRules${index}`, {
securityGroupId: amphoraSecurityGroup.id,
protocol: amphoraSgIngressMap.protocol,
portRangeMax: amphoraSgIngressMap.portRangeMax,
portRangeMin: amphoraSgIngressMap.portRangeMin,
remoteIpPrefix: amphoraSgIngressMap.remoteIpPrefix,
ethertype: "IPv4",
direction: "ingress"
});
}
あとは、openrc認証情報ファイルを読み込んで、npm run build および cdktf deploy を実行します。
$ npm run build > cdk-openstack@1.0.0 build /home/ubuntu/workspaces/gitlab-com/cdk-openstack > cdktf get && tsc Generated typescript constructs in the output directory: .gen $ $ npx cdktf deploy Deploying Stack: cdk-openstack Resources ✔ OPENSTACK_NETWORKING OctaviaVlanProvider openstack_networking_network_v2.OctaviaVlanProviderNetwork ✔ OPENSTACK_NETWORKING AmphoraSgRules02 openstack_networking_secgroup_rule_v2.AmphoraSgRules0 ✔ OPENSTACK_NETWORKING AmphoraSgRules12 openstack_networking_secgroup_rule_v2.AmphoraSgRules1 ✔ OPENSTACK_NETWORKING AmphoraSgRules22 openstack_networking_secgroup_rule_v2.AmphoraSgRules2 ✔ OPENSTACK_NETWORKING AmphoraSecurityGrou openstack_networking_secgroup_v2.AmphoraSecurityGroup ✔ OPENSTACK_NETWORKING OctaviaVlanProvider openstack_networking_subnet_v2.OctaviaVlanProviderNetworkSubnet Summary: 6 created, 0 updated, 0 destroyed. $
ちゃんとデプロイされました!!
所感
terraform providerが用意されているプラットフォームについてはこれで一応インフラコードを高級言語化できそうで良い感じですね! linterは少なくともGitLab CIで実行できるようにしておきたいものです。。。
自宅プライベートクラウドにおけるCDのご紹介
自宅プライベートクラウドをお休みの時間に粛々と構築しています。現在は構築用のコードリポジトリ(ansibleだったり、k8sのマニフェストだったり、docker-composeだったり。。。)に対するデプロイが全て手動で煩雑だったため、CDをGitLab CIにて実現しようと奮闘しています。本日はその模様をお伝えしたく。。。
まず、私はアーキテクチャ図を書くのが好きなので、全体構成の説明です。

結構シンプルでして、インフラコードがGitLab.comにプッシュされましたら (もちろん、プライベートリポジトリ)、自宅インフラ内で動いているGitLab Runnerがそのイベントをキャッチします。GitLab Runnerはその後、AWXに対してPlaybookの実行を依頼します。AWXはHashicorp Vaultに対して、CA秘密鍵で署名されたSSH公開鍵の生成を依頼し、その鍵をもって構成管理対象サーバに接続・Playbook実行を行います。
私はAWXに登録するJob Templateを管理したくなかったので、GitLabのCD過程でその時必要なJob Templateを作っては消すようにしています。AWXを管理するためのplaybookとか、二度手間過ぎて作りたくないし、実行履歴はGitLab上から確認できるので、これで良しとしています。
参考までに、CDで使っている .gitlab-ci.yml をぺたり。lower系のジョブはKVMホストなどのインフラでも基礎となる部分の実行ジョブ、それ以外をupper系のジョブとしてまとめています。。。
stages:
- test
- execute
- cleanup_execute
.common_template: &common_template
image: $DYNAMIS_CI_IMAGE
test:
<<: *common_template
stage: test
script:
- ansible-lint src/*.yaml
tags:
- stg
except:
- master
- tags
.execute_template: &execute_template
stage: execute
script:
- >
awx job_templates create
--name ${AWX_JOB_TEMPLATE_NAME}
--project ubuntu-os-common
--playbook src/site.yaml
--inventory dynamis
--scm_branch ${CI_COMMIT_REF_SLUG}
--become_enabled true
--job_type run
--limit "${AWX_EXEC_LIMIT}"
- >
awx job_templates associate ${AWX_JOB_TEMPLATE_NAME}
--credential ${AWX_SSH_CREDENTIAL}
- >
awx job_templates launch ${AWX_JOB_TEMPLATE_NAME}
--monitor
when: manual
allow_failure: false
execute_stg_lower:
<<: *common_template
<<: *execute_template
variables:
TOWER_HOST: $AWX_HOST_STG
TOWER_USERNAME: $AWX_USERNAME_STG
TOWER_PASSWORD: $AWX_PASSWORD_STG
AWX_SSH_CREDENTIAL: $AWX_SSH_CREDENTIAL_STG
AWX_EXEC_LIMIT: lower
AWX_JOB_TEMPLATE_NAME: &job_templates_stg_lower ubuntu-os-common-execute-stg-lower
tags:
- stg
only:
- master
execute_stg_upper:
<<: *common_template
<<: *execute_template
variables:
TOWER_HOST: $AWX_HOST_STG
TOWER_USERNAME: $AWX_USERNAME_STG
TOWER_PASSWORD: $AWX_PASSWORD_STG
AWX_SSH_CREDENTIAL: $AWX_SSH_CREDENTIAL_STG
AWX_EXEC_LIMIT: all:!lower:!kernel
AWX_JOB_TEMPLATE_NAME: &job_templates_stg_upper ubuntu-os-common-execute-stg-upper
tags:
- stg
only:
- master
execute_prod_lower:
<<: *common_template
<<: *execute_template
variables:
TOWER_HOST: $AWX_HOST_PROD
TOWER_USERNAME: $AWX_USERNAME_PROD
TOWER_PASSWORD: $AWX_PASSWORD_PROD
AWX_SSH_CREDENTIAL: $AWX_SSH_CREDENTIAL_PROD
AWX_EXEC_LIMIT: lower
AWX_JOB_TEMPLATE_NAME: &job_templates_prod_lower ubuntu-os-common-execute-prod-lower
tags:
- prod
only:
- tags
execute_prod_upper:
<<: *common_template
<<: *execute_template
variables:
TOWER_HOST: $AWX_HOST_PROD
TOWER_USERNAME: $AWX_USERNAME_PROD
TOWER_PASSWORD: $AWX_PASSWORD_PROD
AWX_SSH_CREDENTIAL: $AWX_SSH_CREDENTIAL_PROD
AWX_EXEC_LIMIT: all:!lower:!kernel
AWX_JOB_TEMPLATE_NAME: &job_templates_prod_upper ubuntu-os-common-execute-prod-upper
tags:
- prod
only:
- tags
.cleanup_execute_template: &cleanup_execute_template
stage: cleanup_execute
script:
- awx job_templates delete ${AWX_JOB_TEMPLATE_NAME}
when: always
cleanup_execute_stg_lower:
<<: *common_template
<<: *cleanup_execute_template
variables:
TOWER_HOST: $AWX_HOST_STG
TOWER_USERNAME: $AWX_USERNAME_STG
TOWER_PASSWORD: $AWX_PASSWORD_STG
AWX_JOB_TEMPLATE_NAME: *job_templates_stg_lower
tags:
- stg
needs:
- execute_stg_lower
only:
- master
cleanup_execute_stg_upper:
<<: *common_template
<<: *cleanup_execute_template
variables:
TOWER_HOST: $AWX_HOST_STG
TOWER_USERNAME: $AWX_USERNAME_STG
TOWER_PASSWORD: $AWX_PASSWORD_STG
AWX_JOB_TEMPLATE_NAME: *job_templates_stg_upper
tags:
- stg
needs:
- execute_stg_upper
only:
- master
cleanup_execute_prod_lower:
<<: *common_template
<<: *cleanup_execute_template
variables:
TOWER_HOST: $AWX_HOST_PROD
TOWER_USERNAME: $AWX_USERNAME_PROD
TOWER_PASSWORD: $AWX_PASSWORD_PROD
AWX_JOB_TEMPLATE_NAME: *job_templates_prod_lower
tags:
- prod
needs:
- execute_prod_lower
only:
- tags
cleanup_execute_prod_upper:
<<: *common_template
<<: *cleanup_execute_template
variables:
TOWER_HOST: $AWX_HOST_PROD
TOWER_USERNAME: $AWX_USERNAME_PROD
TOWER_PASSWORD: $AWX_PASSWORD_PROD
AWX_JOB_TEMPLATE_NAME: *job_templates_prod_upper
tags:
- prod
needs:
- execute_prod_upper
only:
- tags
自作の量子コンピュータシミュレータ
インフラ畑出身の私ですが、最近はpythonで量子コンピュータシミュレータなんかを書いています。
pythonでコード書いたり、テスト書いたりする練習になるのと、単純に量子情報の研究やっていたので、気になっていたからですね。ですが、単純にアプリケーションに対する考え方が不足していてこれまで真剣に手を出そうとはしていませんでした。業務を通じてこれだけ考え方が醸成できたので、職場の先輩方には感謝感謝です。。。!
実際の開発コードですが、ここで開発しています。
https://github.com/bbrfkr/quantum-simulator
量子コンピュータというと敷居が高そうに感じますが、コアコンセプトとして、量子ビットと時間発展、観測量、結合系の作り方を飲み込めれば、物理学出身でなくても理解することができると思います。↑の開発コードではこのコアコンセプトを数学的に愚直に実装しています。。。
内部的にnumpyを使っているので、できるならば(よく知らないので教えて欲しい。。。)TensorFlowやPyTorchなどの機械学習ライブラリを使って高速化&GPU活用をしてみたいなーと夢膨らませたり。。。
これでKubeFlowとか使えたら、CNDTのネタになったりしないかなー。。。難しそうですけど。
もし筆を動かす気になれば今後、コアコンセプトである量子ビット、時間発展、観測量、結合系について解説していければと思います!本日はこの辺で。。。
Hashicorp Vault 触ってみた
前々からHashicorp製品群には興味がありましたが、試そう、試そうと思うだけで中々本格的に手を出せずにいました。なんというか、Hashicorp製品群を本格的に利用しようという考えにまでならないんですよね。。。
Vagrant知ったときはインフラしかできなかったので、「仮想マシン自分で作ればいいじゃない」となってしまい、Terraformに興味を持ったときはOpenStackやAWSにどっぷりだったので、「CloudFormationやHeatでいいじゃない」となってました。NomadやConsulなんかもありますが、コンテナオーケストレータとサービスメッシュはKubernetesとIstion & Linkerdが押さえている状況なので、これも必要に迫られて、というのは中々なさそう。
その中で最近唯一本格的に触ってみたい、触ってみなければ! と思っているのがVaultです。
なんでVaultかというと、自宅プライベートクラウドを作ろうとしたときに各コンポーネントをコンテナで立てるのは良いのですが、コンテナを実行する基盤自体は仮想マシン、もしくは物理マシンになります。OSレイヤ以下をメンテナンスしなくてはならないので構築、運用負荷がそれなりに高いわけですが、なるべく負荷を下げるためにInfrastructure as Codeを積極的に実践していこうと思っています。そうするとコードに機密情報を与えるにはどうすればよいか。。。となったわけです。
クラウド上であればAWS Secrets ManagerやAWS KMSなどのシークレット管理サービスが存在するのでいいのですが、非クラウド環境においては個別にそれらに対応するソフトウェアを探すか、手動に甘んじるしかありません。そこでクラウドネイティブなシークレット管理ソフトウェアを探して真っ先にたどり着いたのがHashicorp Vaultだったということです。
今回は月並みに「触ってみた」ということで、以下の流れで簡単にCLIでシークレットを取得するまでを見ていきます。
- サーバ構築 - Seal/Unseal
- シークレットの登録
- Policyの設定
- ユーザの設定
- ログイン - シークレット取得
サーバ構築
構築と言っても公式でdockerコンテナが用意されているので、基本的にはconfigファイルを作成して、server 引数をつけてコンテナを起動するだけです。しかし、Vaultはただ引数を指定して、サーバを初期化しただけではいきなり使えるようにはなりません。使える状態にするためにはUnsealという作業が必要になります。
Vautlは起動直後(再起動時も含む)またはSeal操作後にSeal状態となります。これはシークレットがどこに保存されているかはわかっているが、暗号化されたシークレットを見る、つまり復号化する手段を知らない状態です。したがって、初期化時に生成された復号化するためのキーを閾値の数まで入力して、復号化に必要なマスターキーをVaultに持たせてやる必要があります。
初期化とUnsealを一括して実行できるpythonスクリプトとセットでリポジトリを作成しましたので、よろしければご利用ください。なお検証のため、APIはhttp通信を前提にしておりますので、検証でのご利用か、必要に応じてhttpsに変更してご利用くださいませ。
ちなみにSeal状態の画面をパシャリ。

シークレットの登録
さて、サーバを起動してUnseal状態になったら、secrets/secrets.yaml に書かれた root_token を使ってログインします。

ログインするとこんな画面になるので、早速Key-Valueなシークレットを作っていきましょう!




適当に test-secrets というシークレット名で password: p@ssw0rd という不届きなKey-Valueを登録してみます。


これでOK!
Policyの設定
次にPolicyを作成していきます。VautlにおけるPolicyは今の私の理解だとIAM Policyのようなもので、どのシークレット(厳密にはAPIサーバのURLパス)をCRUDできるのかを決めるものです。Policiesメニューから作っていきましょう。

今回は先程作った test-secrets シークレットを読み込めるだけのポリシー test-policy を作ってみます。


はい。
ユーザの設定
PolicyはIAMポリシーのようなものといいました。次はポリシーを割り当てるユーザ、IAMユーザのようなものを作っていきます。Accessメニューから行きましょう。




雑に id = test-user, password = test なユーザを作ります。

Policyとユーザとの紐付けは Generated Token's Policies で行います。


できました!
ログイン - シークレット取得
これで準備万端(?)です。CLI経由で用意した test-user で test-secrets の中身を見てみます。まずはログイン。

ログインできたらtokenがVaultから渡されるので、VAULT_TOKEN 環境変数にこれをセットして、kv get コマンドを実行します。

ただ p@ssw0rd が取れただけだけどすごく嬉しい。
ちなみに、-format オプションで出力をjsonにできたりもするので、jq ヘビーユーザも大歓喜ですね!

おわりに
一通りVaultの User & Password での使い方を見てきました。他にもApplicationに組み込む形に最適化された AppRole という認証方式や、Key-Valueだけではなくて PKIシークレットなんかも管理できます。またAWXではサーバへの認証キーをVautl側で管理できたり、KubernetesでもAgent-injectorなんてものがあったりと、シークレット情報をVaultで一元管理するために役立つ公式 & 3rd Partyツールが賑わっているようです! この記事をご覧になって興味が湧いた方はまずは以下のリポジトリで体験いただければ幸いです。
自宅プライベートクラウド再構想
生きています! 過去の自分よ、ごめんなさい。。。もうそれ以上は言うまい。。。
さて、自宅プライベートクラウド環境ですが、構成管理ツールで構築・運用を自動化しているものの、やはりVMに直接ソフトウェアをインストールするとなるとペット的に扱わざるを得ないので、アップデートしなくなり塩漬けになる、という問題をはらんでいました。OpenStackは半年でアップデートされるので、もう少し気軽に移行できるようにしておきたい。。。
そう思い立ち、全てのコンポーネントをKubernetes上でコンテナとして扱うことにしました。Yahoo!さんがやっているようなOpenStack on Kubernetesですね。これを自宅でも実現したいということです。今回はこの構想について紹介したいと思います。なお、Keystone、Swift、Glance、Nova、Neutron、Horizonまでは検証済みで、動いた実績のある構想です。
物理構成
物理構成は以下の図のとおりです。8台の物理サーバと1台の1G L2SW、1台の10G HUBを用意しています。図を見ていただければ解ると思いますので、特筆することは無いです。機械学習などの重い処理を動かすことは想定していないので、CPUに関してはこだわりなく、非力なものを使っています。メモリ特化です!

仮想構成
仮想的な構成は以下の図のとおりです。仮想的な構成とはここではVMまでに拡張した構成を表すとします。
KVMホスト表記されている1台はNATルータとAWX&Vaultサーバに分割し、残った3台はKubernetes Master・Worker、etcdと負荷分散用のLBを入れ込んでKubernetesを稼働かつ、OpenStackのコントローラコンポーネント群を動かします。
Nova-ComputeホストおよびCeph-OSDホストはベアメタルでkubeletを載せて、Kubernetes Workerノードとしてそれぞれの役割で利用します。

コンポーネント相関
プライベートクラウドを構成する各要素の関係も図に示してみました。今回、先程からCeph-OSDと言っているようにストレージとしてはCephを用います。Cephクラスタは自前でCephコンテナイメージを作ってたててもいいですが、CNCF Incubating ProjectとしてコミュニティマネージドなCephオーケストレーションツール(Cephだけではないですが。。。)であるRookを使い、省力化しています。基本的にコンピュートは冗長構成を組みますが、リソースの関係上冗長化することができない、しても無意味なところ(NATルータなど。2プロバイダ契約ではないので、冗長化しても効果が薄い)はSPOFのままです。一人でこれだけの量のコンポーネントを見ることになるのでEFKスタックとPrometheus&Grafanaを使ってログ収集・可視化、メトリクス監視・可視化はしっかり行っていきます。。。

ベストエフォートで今後、Keystone以降の組み方も記事を書いていきたいと思います。。。